

Industries involving payment and transactions are prone to financial and credibility losses and fraud, and the threats are growing. Many businesses underestimate the risks and jeopardize themselves and their customers, resulting in high fraud rates. There is proof of PwC’s Global Economic Crime and Fraud Survey conducted in 2020 among 5,000 respondents for the last 24 months. The numbers are disturbing: the total cost of these fraud losses reached $42 billion. Do you know what’s even worse here? A big part of these businesses ignored the crimes; only 56% of respondents investigated their worst fraud cases imperiling their security and credibility.
With the expansion of online banking, BaaS, and digital payment systems, the number of transactions has become exponential, leading to increased vulnerability points. At the same time, following the new trends, fraudsters adapt to them inventing innovative fraudulent schemes. This has provoked businesses to look for more sophisticated and robust fraud detection models and management systems.
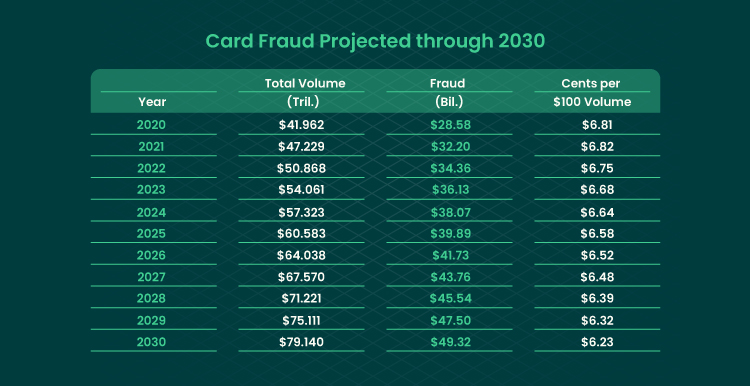
Card fraud is the most widespread phenomenon across industries. According to the Nilson report, in 2020, global fraud losses reached almost $29 billion and are projected to be $49,32 billion in 2030.
The traditional fraud detection platforms following the rule-based approach entail fraud detection scenarios written by data scientists. And that means manual reviews, slow evaluation of data sets, and inaccuracy. As an alternative to fighting fraud crimes, machine learning beats conventional approaches that allow faster processing, instant learning of historical data, and process efficiency.
Let’s compare rule-based vs. ML-based fraud detection to understand what you really need to consider while struggling against sophisticated and tech-savvy fraudsters.
Rule-based vs. ML-based Fraud Detection Systems
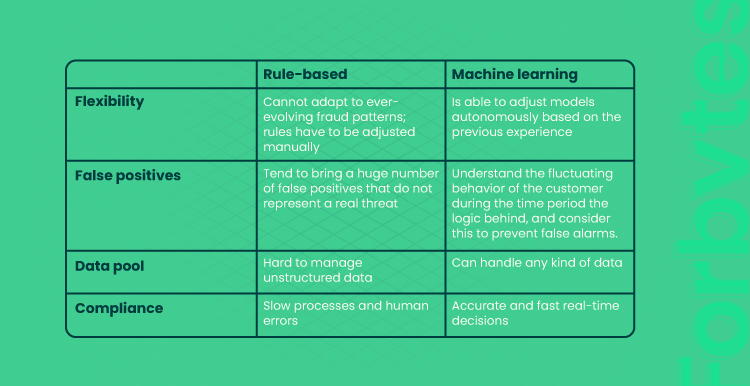
Rule-based fraud detection systems use straightforward analytical models in the “if-then” logic format. To detect suspicious behavior, rule-based systems entail pre-defined scripts that cannot manage real-time data streams. The evaluation of fraud detection is conducted by data and fraud analysts and e-commerce security teams, which means employees must manually review transactions. This leads to inefficient time spending, time waste, and expensive training. Moreover, while manually checking the transaction, customers will be frustrated with slow order fulfillment. This, in turn, will result in a bad customer experience.
And here comes one more issue relating to blocking genuine customers, aka false positives affecting lost transactions and hindering revenue opportunities. To understand the principle, let’s take an example. If a user exceeds the spending threshold with the credit card or uses the card in a high-risk location, the activities are identified as fraudulent. In this case, rule-based systems come into play by enabling the pre-programmed script to block such types of transactions. But it does not mean that the number of exceeding thresholds or the usage in the risky regions is for sure the determinant of fraud. Unfortunately, such false positives can affect the acquisition of genuine customers.
However, this is not the only disadvantage of the traditional rule-based approach. In the digital era, fraudsters are evolving and have gained more sophisticated skills in coming up with fraud patterns. That’s why the complexity of fraud also increased. Therefore, new rules have to be developed when new fraud patterns appear. Lockdown restrictions have driven the rapid adoption of digitalization and tools for online transactions. This led to more diverse and complex fraudulent schemes: fake websites, fake delivery services, online bookings, etc. Therefore, to boost the fraud detection and prevention market, machine learning and artificial intelligence need to be involved in processing large data sets.
Machine learning systems enable algorithms to process massive data sets instantly and permanently, analyze and recognize patterns, and make predictions with the ability to learn from historical fraud patterns (past experience). Therefore, ML does not require to be manually programmed with plenty of pre-determined rules to spot fraudulent cases. Such algorithms facilitate the system to respond to various cases. Being trained with information about previous fraud experience, they are able to identify and assess the pattern autonomously.
With machine learning, the process of fraud detection is much more accurate. It is conducted in a more granular way, making the outcomes more effective and prompt and eliminating human involvement. Furthermore, once gathered and categorized, the information is labeled as good (legitimate) or bad (fraudulent). Based on these labels, fraud prevention programs powered by ML can anticipate future criminal activities. As soon as they identify the fraudulent situations, they update their models to use them in the upcoming threats.
In terms of customer experiences, banks used to enhance security measures by overwhelming users with a number of verification steps to pass a transaction. As in the case of false positives inherent to rule-based systems, machine learning algorithms can analyze the user’s habits, experiences, and behaviors during a specific time to reduce the cases of false positives. So that if a customer exceeds the credit card threshold in an unusual place, an ML-based algorithm will incorporate data analyzed about this customer during a specific period of time. For instance, a customer’s travel time or purchasing a ticket to an unusual place. Now you know how to decrease the false positives with ML and increase positive customer experience.
Machine Learning vs. RuleBased Approach: Comparison
Why Should You Use Machine Learning in Fraud Detection?
- Speed. Opposite to rule-based systems using ad hoc generation rules, machine learning algorithms manage to process hundreds of thousands of queries in real-time in microseconds, which positively impacts the speed of transactions, especially valuable in eCommerce.
- Scalability. As soon as the customer base expands, rule-based systems are incapable of coping with extensive data sets. Machine learning, on the contrary, benefits from more data. The more data, the more effective models for defining genuine and fraudulent customers.
- Accuracy. To avoid the blocking of genuine transactions, machine learning comes into play by identifying subtle and non-intuitive patterns. This is hard to obtain using a rule-based approach. The use of ML in fraud detection results in accurate and granular decisions that greatly contribute to false positives elimination.
How Does ML-based Fraud Detection System Work?
- Data input. The first step to detect fraud is data collection and segmenting. At this stage, the more data is gathered, the more solid the algorithm developed by ML will be. ML models receive data sets to be trained to predict the value of the possible outcomes.
- Extract features. At this stage, features that describe fraud signals and customer behaviors are extracted. They are broken into primary categories: customers’ preferred payment methods, details about the orders, location, identity, and network alternatives.
- Training algorithm comes into play. It represents a data set of rules that machine learning must adhere to comprehend the difference between legitimate and fraudulent activities and make accurate predictions.
- A specific model. Once the training is finalized, your company gets a model specific to your business. To keep up with the latest fraudulent schemes, the model has to be regularly improved and updated.
There are two common ML-based anti-fraud approaches (types of models): supervised and unsupervised.
Unsupervised models are designed to detect outlier transactions, behaviors, and anomalies representing previously unknown forms of fraudulent activities. These models are created from data that is not tagged and labeled. On the contrary, supervised models represent input information that is tagged as good or bad to detect which anomaly activities are fraudulent or unusual. Supervised models are trained by a huge number of tagged historical transaction details.
There are various methods of applying both supervised and unsupervised models; however, in this article, we will cover supervised methods since they are usually used when creating more complex projects.
Supervised Fraud Detection Methods
Let’s first present the two simplest methods: the logistic or linear regression and the decision-tree-based method.
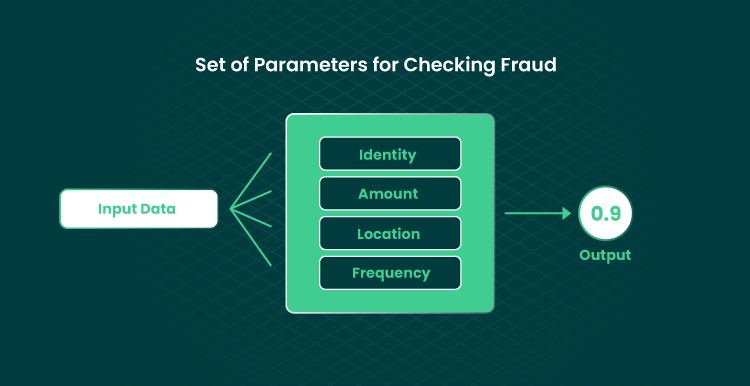
Logistic regression is a method that evaluates cause-and-effect relationships in structured data sets and predicts the probability of a target variable. Variables are binary in nature. Based on the set of parameters for checking fraud (identity, location, frequency, etc.) and categorical decisions (either fraud or non-fraud), the probability of the output is calculated (either 0 or 1).
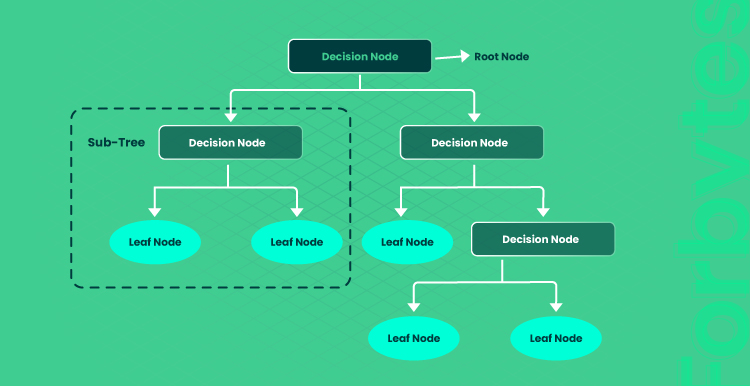
For more progressive outcomes, you can use a decision-tree-based method that is more mature and is designed to classify unusual activities. The decision-tree algorithm is a tree-structured scheme that entails nodes and branches (see the scheme below). This algorithm allows for the structure containing the decision node used to make decisions with branches representing the decision rules, and leaf nodes that are the outcomes. A leaf node is the ultimate outcome of the decision without the possibility to divide further. Based on the yes-no answer, a decision tree is subdivided into sub-trees.
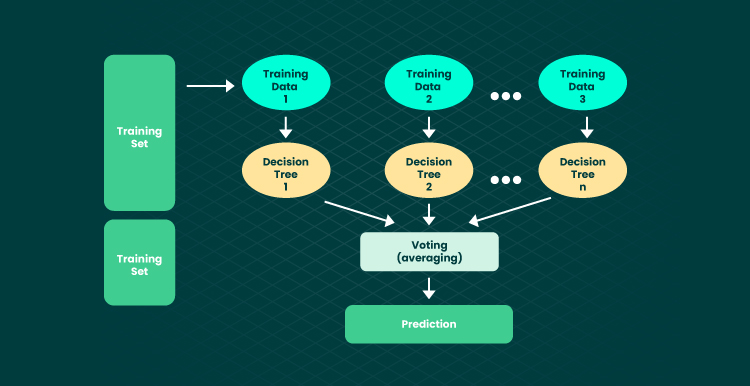
Random forest is another type of machine learning model that beats decision trees due to the concept of ensemble learning. The method combines numerous decision trees for enhanced outcomes and predictive accuracy. Compared to other algorithms, random forest excels owing to high accuracy even if the large data set is missing. Also, it takes less training time to teach the algorithm.
Neural networks function similarly to the human brain’s neurons employing several layers. Artificial neural networks (ANN), aka deep learning models, are highly applicable for businesses producing huge amounts of data points. Therefore, they can solve complex tasks. Thanks to the multi-layer principle, neural networks can train on a multitude of features and easily scale up. Although the deep learning approach is profound, it loses its power once there are no millions of labeled transactions. With several layers in a neural network, data undergoes a variety of parameters that can be more business-specific.
Machine Learning in Fraud Detection: Scenarios
There are a variety of fraud scenarios across industries where machine learning technology can bring tremendous results. We will cover only the most widespread ones. During the coronavirus lockdown, the UK suffered from a sheer number of frauds and scams, including smishing emails pretending to be sent from the government and offering tax refunds, phishing emails requesting updated payment information, and other scam emails. In 2020, the losses related to unauthorized financial fraud in the UK amounted to $1,66 billion. Payment card fraud and Authorized Pushed Payment (APP) scams were the top fraud activities: 45% and 38%, respectively.
Identity Theft
Classified as a cybercrime form of fraud, identity theft entails robbing a user’s identity connected to bank accounts, email addresses, passwords, etc. Among the most spread signs of identity theft are unfamiliar credit card activities, unauthorized transactions, missing bills, bank account discrepancies, odd calls from debt collectors, denied medical claims, and others. It is worth classifying identity fraud as:
- First-party fraud (committed by a person who represented their own identity but with fraudulent intent);
- Third-party fraud (performed by the intruder who distorts their identity and pretends someone else stealing the ID of another person who is not aware of this intent);
- Synthetic identity theft (is the most complex and progressive type of identity theft aiming to deceive businesses; combines plenty of real and fake data pieces that belong to different people).
Synthetic identity fraud is geared toward creating a fictitious identity to perform fraudulent activities. It is the fastest-growing crime while at the same time being the most difficult one to detect. Called a “Frankenstein” identity, this type of financial crime is nurtured for years. It is estimated to cost banks 6 billion annually, CNBC states. What’s interesting, 95% of synthetic identities were not revealed as fictitious ones. Moreover, they even turn into desired customers after some time.
Machine learning algorithms come into play to assess a user’s habits and transaction data more effectively than traditional fraud detection systems. And exactly here, machine learning technology can combat fraud in a more sophisticated and smarter manner. Since machine learning operates in accordance with a person’s behavior, it can detect impersonated fraudsters as well. By collecting a vast amount of historical data, ML algorithms can precisely predict the outcomes.
Electronic Payment Fraud
According to Nilson’s report, in 2019, $28,65 billion was the number of gross fraud losses tied to credit and debit card payments, (except QR-based and pushed payments from one bank account to another).
With the increasing adoption of CNP (card-no-present) and P2P, especially due to COVID-19, the number of frauds has exploded. While credit card fraud is the fastest-growing phenomenon of identity theft, Javelin Strategy $ Research revealed that card-no-present fraud is 81% more predominant than payments with physical cards. The reason behind this is that in CNP payments, there is no possibility to check the user’s photo ID or confirm signatures.
Nowadays, P2P payments are at their peak, and online mobile payments in the US are going to double from $321 billion in 2020 to $634 billion in 2024. eCommerce marketplaces are considered easy targets for fraudsters who can either buy services and products by creating fictitious accounts with stolen card info or deceive buyers and sell services to them requiring payment via digital apps. Moreover, there is a fraudulent tendency to create fake IDs.
As you see, online shopping is at high risk of undergoing fraudulent schemes, which are getting more sophisticated nowadays. Without machine learning and unsupervised ML capable of detecting fast-growing fraud patterns, combating digital payment fraud and keeping pace with modern approaches would be an ineffective “endeavor”. Self-learning models reduce the training time and are able to provide holistic data analysis across the entire customer account life cycle.
Apart from eCommerce and finance industries, there are also many use cases in other spheres, such as insurance and healthcare. For example, fraudulent insurance claims where a fraudster distorts real incidents, misrepresents the case of the incident, its nature, etc. Based on the historical dataset of an insurance claim, machine learning algorithms can label claims as fraudulent or legitimate ones.
Final Word
As long as prodigious opportunities emerge in the digital marketplace, fraudsters are coming up with more complex and quick-witted scenarios of hijacking control over data. According to the Nilson Report, the gross global losses amounted to $28,65 in 2019, and this number is projected to rise. Artificial intelligence and machine learning are the top drivers of fighting online fraud.
Leveraging supervised and unsupervised ML models, businesses can be more successful in detecting fraud. While supervised algorithms are manually intensive and can detect fraud based on labeled data, unsupervised ones can detect anomalies in a novel, more sophisticated manner. Nonetheless, ML algorithms have to be self-tuned with time and adapted to emerging scenarios of modern fraudsters.
If you are looking for ML specialists to hire who may help you build an effective anti-fraud system in your organization, let us know. We will be happy to provide you with top-notch engineers in this field.

Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?
Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?





