

According to Statista, the number of digital buyers is projected to reach 285 billion by the end of 2025. This growing e-commerce trend inspires businesses to look for innovative solutions to client pain. They integrate AI/ML tools to offer smarter services.
Product matching in ecommerce has recently become a hot topic among retailers. They use a product matching system to ensure a great buying experience and take full advantage of selling online. Well‑implemented product matching contribute to higher conversion rates and stronger customer loyalty by serving up the most relevant offers instantly.
Some retailers provide unique offers to their clients to stand out. Others offer common products and put effort into staying competitive. In this article, we will talk about product matching in eCommerce. We’ll also explore the most important deep-learning algorithms for making the right product matches.
What Is Product Matching in Ecommerce? A Quick Guide
A mobile-first approach to software development has changed the way people shop. Retailers and buyers operate in an advanced eCommerce environment. Online purchases, transactions, and order fulfillment are made quickly and with no effort. As a part of the digitalization trend, eCommerce businesses use product matching.
Nowadays, people look through different e-commerce platforms to find the needed product at the best price. The most popular eCommerce platforms are Shopify, Magento, Squarespace, WooCommerce, etc. Magento.
Dwelling upon the topic, retailers use different eCommerce spaces for selling their products. And it happens that identical products are offered by different retailers on the same platform. A user searches for a specific product and sees the same offer made by different sellers in one place. The consumer compares product price, attributes, and quality and then chooses the best offer.
The situation is analogous to the case when a buyer visits multiple physical stores in search of the most advantageous offer. The difference is that an online decision is made effortlessly and quickly, without the need to leave home. How does technology help a buyer to make an informed choice based on product comparison? The answer is product matching.
Product matching uses AI algorithms to compare titles, attributes, and images, allowing customers to easily identify identical or similar products across various sellers. This not only improves the shopping experience but also supports more efficient inventory management by reducing duplication, streamlining listings, and helping sellers maintain accurate stock levels across multiple platforms.
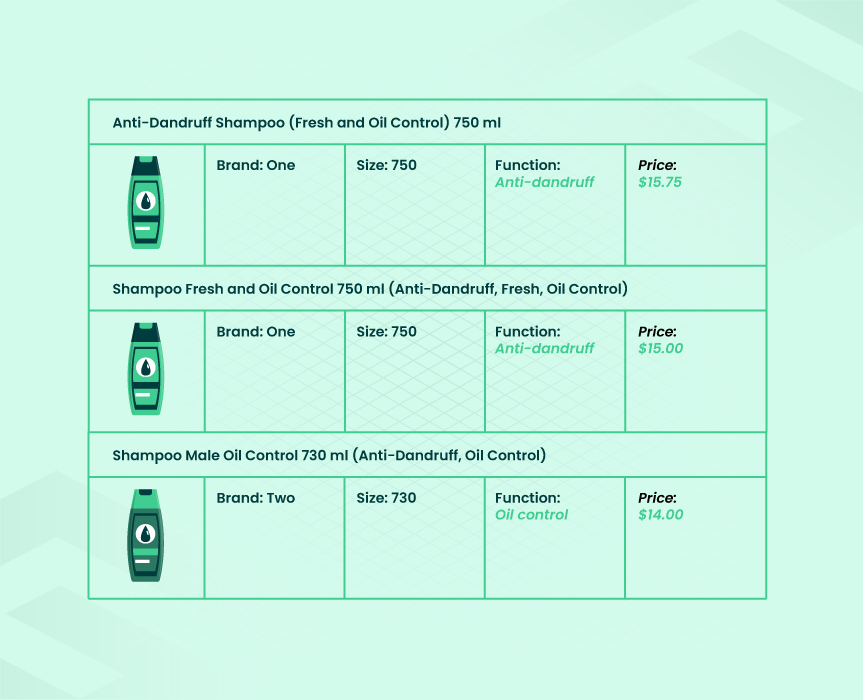
How Product Matching Helps Both Sellers and Buyers
Product matching in ecommerce means using deep learning to present the same products offered by different sellers in one search result. Product matching solutions are important for both retailers and online shoppers.
For consumers, product matching is the opportunity to choose the best offer after comparing all available options. Suppose that a consumer wants to buy a table lamp. The main argument in favor of a specific offer will be the price. They visit a specific marketplace and begin comparing the options.
It turns out that two sellers offer the same table lamp for $50. Meanwhile, another seller says, “Buy the lamp for $53 and get a table clock for free!” The price-quality ratio seems more attractive in the second case. If a client needs a table clock, the second option will be more valuable for them. To enable comparison, product matching puts the same offers into one search result and ensures flexibility and convenience for a client.
For a retailer, product matching can be used for developing a rational price policy and keeping a business competitive. When businesses compare product prices on different platforms, they learn more about their competitors and make products stand out. The special offer where the table lamp is sold with the table clock is an example of how a seller can differentiate.
Besides, product matching in ecommerce comes in handy when a retailer wants to make the right offers. To help clients find their product, businesses need to name it in a particular way, use images, and add the right product attributes. Product matching also helps to trace tendencies and learn from the competitors’ behavior.
In a broader context, product matching doesn’t just enhance customer experience; it also strengthens business operations. By identifying identical products across multiple listings, retailers can improve inventory management, avoid redundant stock, and ensure better organization of their digital catalogs. At the same time, analyzing matched product data enables a smarter pricing strategy, helping businesses adjust prices based on market trends, competitor offers, and customer preferences. As a result, product matching becomes a powerful tool that supports both strategic planning and day-to-day ecommerce performance.

Top Product Matching Models for eCommerce Success
Usually, product information on e-commerce platforms consists of a title, attributes, and an image. A product title is a brief text identifying the key information about a product. Product titles consist of a product name and its characteristics. For instance, a plaid shirt male. Product attributes provide more details on the product and are usually based on name-value pairs.
To standardize the way sellers present product attributes, they use categorization or structured tables. If we talk about the male plaid shirt, product attributes added on a website may include color and size, information about the fabric, and the manufacturer. Product images illustrate what a product looks like. Sellers tend to borrow the same product image from one another.
Borrowing (or sometimes stealing) an image from competitors makes it easier for a customer to detect identical options. But this approach also reduces the chances that a client will pay attention exactly to your offer. That’s where product matching comes into play, analyzing titles, attributes, and images to detect duplicates, unify listings, and present cleaner search results. But how to enable bug-free product matching? We’ll discuss a few examples of product-matching algorithms below.
Effective product matching doesn’t just improve search accuracy; it also helps retailers gain control over critical aspects of their business. A well-trained product matching model recognizes similar or identical products even when descriptions, images, or attribute formats differ. This capability supports smarter inventory management by reducing duplicate entries, improving catalog accuracy, and helping sellers keep better track of their stock. At the same time, it enables a more strategic pricing strategy, allowing businesses to monitor competitors and adjust prices to stay competitive. Ultimately, robust product matching drives both operational efficiency and better customer experience—two essentials in a fast-moving ecommerce environment.
Want to boost your online store’s revenues? Contact Forbytes to implement intelligent product matching tailored to your business needs.
Title match
The title similarity module is an ML-powered product-matching solution. ML compares offers by quantifying the similarity of the titles. The technology easily detects the same titles even if the comparison strings significantly differ.
Suppose several retailers make the same offer of the latest iPhone 15 Pro Max. This is what they might put in the title:
-
iPhone 15 Pro Max
-
iPhone 15 Pro Max 6.7‑inch
-
Apple iPhone 15 Pro Max
-
iPhone 15 Pro Max Sierra Blue
-
iPhone 15 Pro Max 512 GB Unlocked
As you see, the titles for the same product differ from seller to seller. Identifying identical products depends on the model you choose. In this case, to detect the same offers, ML should implement a particular product-matching algorithm illustrated below. The algorithm helps evaluate the degree of similarity and puts identical products in the same search result. Title similarity is one of the core techniques that makes product matching more accurate and scalable across large ecommerce catalogs.
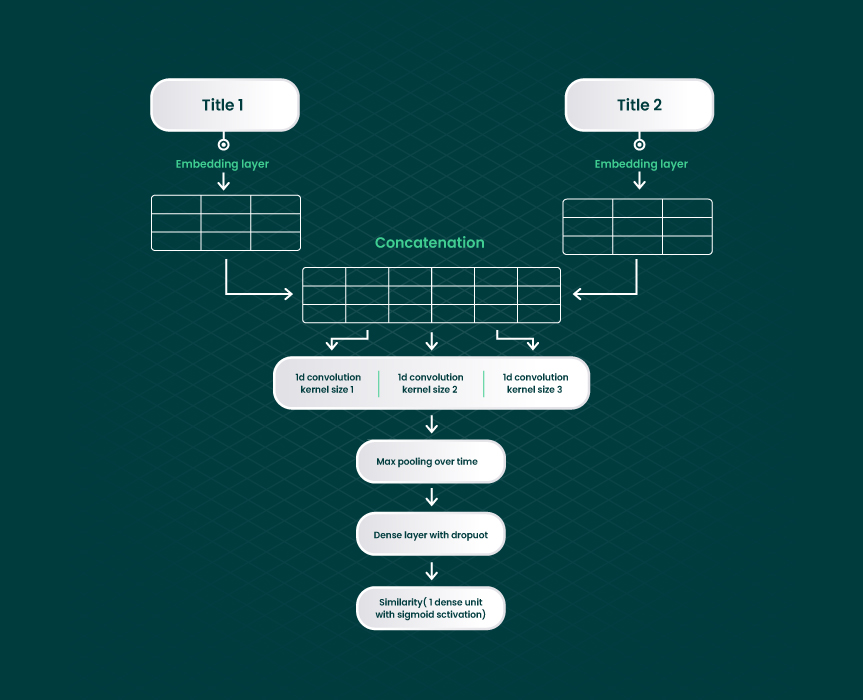
The first step in the algorithm is preprocessing based on pointwise mutual information. Preprocessing allows ML to see two different tokens as a single entity. This, in turn, enables us to further compute the word-level embeddings. In the first layer, word-level embeddings are trained on the title data from the whole catalog. Training enables deep learning technology to correctly handle valuable data that wasn’t trained initially.
Next, the concatenated padded titles are used to train a convolutional network and check if the title length is equal in every option. For this purpose, the skip-gram model can be utilized. And what if one title contains more/less word-level information than another one?
To prevent errors, we take a random title and pair it with the same title that randomly lacks some tokens. After adding them as a matched pair, we expand the capability of the title similarity measure. Accurate title matching not only improves search quality but also strengthens inventory management by reducing catalog duplication and keeping product listings consistent across platforms.
Price match
Product similarity is identified based on the comparison of prices. For instance, there is a range of the same products with approximately the same pricing. One offer stands out from the rest, which may point to the fact that the product is different. This principle works and vice versa. To detect similar offers, price distribution is analyzed. In case of similarity, products are displayed in the same range.
There are two data analysis algorithms used to detect price similarities. The first, price outlier detection, is used to detect price similarity when one price is compared to a group of products with similar prices. The test is used when a price is higher or lower compared to the pricing of this product group. The second data science algorithm, clustering, helps understand the volume of similar products based on their price. The learned data can be applied as a feature in the overarching system of product-matching algorithms. This approach not only improves product grouping accuracy but also supports a more dynamic and competitive pricing strategy by revealing patterns and anomalies in the market.
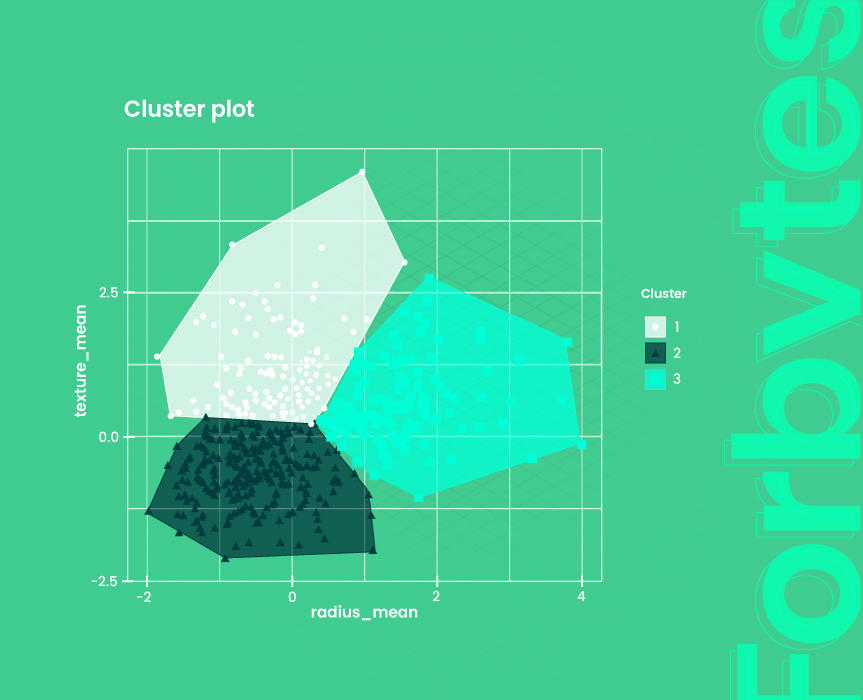
Attribute match
Under this product matching algorithm, product match is based on the similarity of product categories. These can be item size, brand, color, condition, model, etc. The technology launches data analysis algorithms and measures the level of discrepancy between products. In case of low discrepancy, the items are considered the same. The following network can be used for extracting the product attributes:
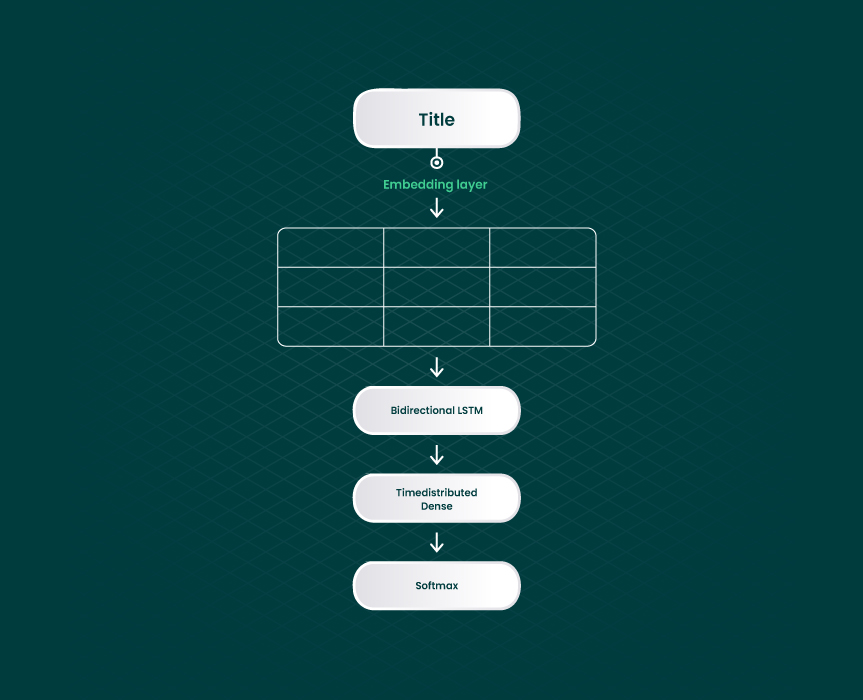
Product attributes can fall into 2 categories: limited range values and endless values. Limited range values have a fixed range of values. With the help of one-hot encoded vectors, these values can be transformed into ML-processed formats. Also, we can apply a convolutional neural network, similar to the one in the title similarity algorithm. It will differ in the output (since there will be only one product title) and in the last layer (since it will be changed to SoftMax).
Meantime, endless values do not have a fixed range. As the range is growing, the accuracy of ML models takes a hit. To solve this problem, we apply attribute extraction in the form of sequence labeling. Under this scheme, every title is tokenized and gets one of the three labels. The labels denote the first or intermediate token or mark that the token is not a part of a brand name. A well-designed product matching model recognizes these attribute patterns accurately, ensuring better identification of product similarities across diverse and complex catalogs.
Image match
Image similarity is based on the same principle as title similarity. To detect the same products, the process of quantifying image similarity is involved. The main challenge of image similarity occurs when there are not enough labeled data points on the product. Moreover, the images of the same product may differ in perspective (as seen below), color temperature, color brightness, etc.
To reduce the volume of manual processing of image pairs, you can apply auxiliary taxonomy to training image-based models. This indirect method allows us to view a particular product in a chain of nodes in the taxonomy. For example, a product may belong to the Clothing > Woman > Blazers node. While exact match on images is ideal, image similarity models help approximate matches when perfect duplicates aren’t available, improving overall product matching accuracy.
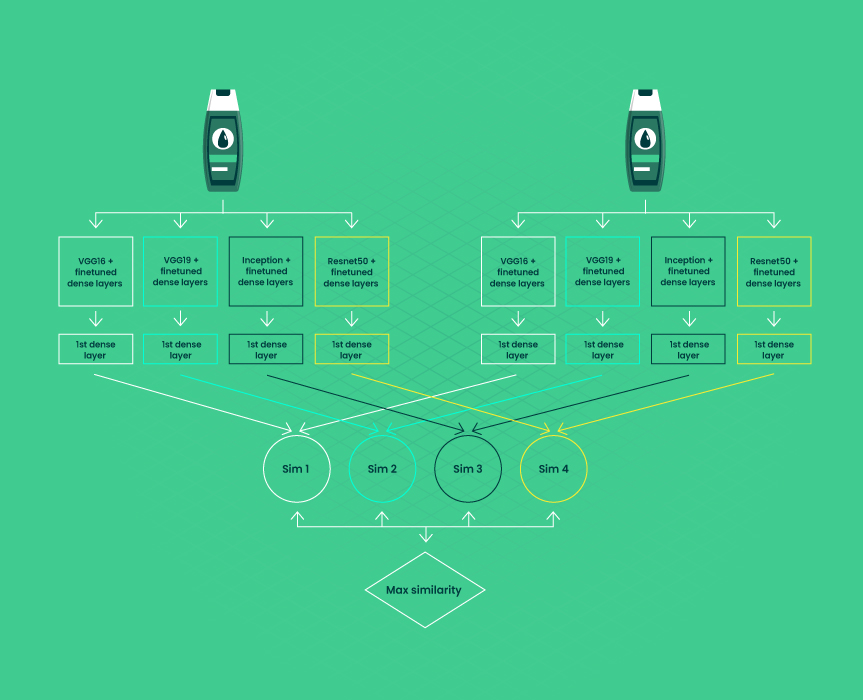
Under the given product matching algorithm, we use the first layers to extract features and compute cosine similarity. It is better to apply several architectures. The more models you use, the more idiosyncrasies you’ll be able to handle in the future.
Contact Forbytes today to implement smart product matching and transform your ecommerce business!
Beyond Basics: Product Matching Uses in Ecommerce
Apart from helping a client find the right product, ML-powered matching algorithms are useful in the following cases:
Making relevant product recommendations
With product matching, businesses grow their sales by suggesting additional options for similar or identical products to their clients.
For instance, a buyer looks for a remote control for a particular device. They put the chosen item into their shopping cart, and the system suggests buying batteries. The product recommendation is relevant for the client, and they purchase both products. Instead of earning $50, a store earns $55. Multiply this figure by the number of your clients, and you’ll see how much your profit can increase.
Establishing competitive pricing
As mentioned above, the price comparison model brings advantages not only for the customer. Ecommerce businesses also benefit from using deep learning algorithms in shaping their product pricing. Machine learning enables them to automate pricing analysis and track tendencies of how prices change over time.
With price intelligence, a business can increase profits. Manual solutions are not that effective because they require human-based research and manual extraction of product data. It slows down training data processing and reduces the value. Moreover, if done manually, pricing analysis impedes business scalability because the process depends on time and resources. By using ML-powered tools, businesses can implement dynamic pricing strategies that adapt to real-time market shifts, competitor actions, and customer demand, maximizing revenue with minimal manual effort.
Improving product listing
With deep learning in ecommerce, you can improve the way your products are listed. Technology-powered analytics allows you to learn more about client behavior and understand how to better rank products in the list.
You can take matched stores and drive the analysis of competing listings. Trained algorithms on competing listings provide you with insights into the way products are described and titled. Analyzing different sections of identical products helps to detect gaps in presenting an item. For instance, detecting the right keywords may increase the chances that your offer will be ranked high in the general list. As a result, you digest the given output and get the tools to increase conversion. Product matching software plays a key role here by automating the comparison of listings and helping sellers position their products more effectively to boost visibility and conversion.
Detecting copyright infringement
Ecommerce businesses spend thousands of dollars on building a solid brand identity. They build e-commerce solutions, write unique content, make catchy product descriptions, and develop attractive designs. Surely, they do this to differentiate and stand out from the crowd. Making unique offers is of the utmost importance for retailers. This is why prompt detection of copyright infringement is crucial in e-commerce.
We can apply the image similarity model to detect cases when a company’s design is stolen by another business. To reinforce the results, the title similarity model can also be used. Using titles as input, we facilitate the search process. When combined into a single product matching model, these tools allow for accurate identification of potential copyright violations, even if the surrounding information or descriptions differ from the original. This ensures faster detection, better brand protection, and greater control over your product listings.

Practical Guide: How You Can Implement Product Matching in Your Store
Ready to get product matching up and running? Here’s a simple, step‑by‑step approach you can follow, even if you’re not an AI expert.
Step 1. Collect & clean your data
- Gather your product catalog: titles, attributes (size, color, brand…), and images.
- Remove duplicates, fix typos, and standardize attribute names (e.g. “colour” → “color”).
- The better your data, the smarter your model will be.
Step 2. Preprocess for AI
For titles & attributes:
- Use a text‑embedding library (like Hugging Face’s SentenceTransformers) to turn each title/attribute into a vector.
- Normalize text to lowercase, strip punctuation, and tokenize.
For images:
- Resize to a standard dimension and apply simple augmentations (flip, crop) if needed.
- Extract image embeddings using a pre‑trained CNN (e.g., ResNet, MobileNet).
Step 3. Choose & train your models
For the title match model:
- Feed your title vectors into a similarity measure (cosine similarity) or a simple Siamese network to learn which titles match.
For attribute matching:
- One‑hot encode fixed attributes; use sequence‑labeling (e.g., a small BiLSTM) for open‑ended ones like product names.
For image match:
- Train or fine‑tune an image‑embedding model so that visually identical products end up close in embedding space.
Step 4. Combine into a product matching pipeline
For each pair of listings:
- Compute the title similarity score
- Compute attribute match score
- Compute image similarity score
- Combine (e.g., weighted average) to get a final “match probability”
Tune your weights (titles vs. attributes vs. images) based on validation data.
Step 5. Deploy & integrate
- Wrap your models in a simple API (using Flask, FastAPI, or AWS Lambda).
- Plug the API into your frontend search or catalog‑management system.
- Whenever a new product is added, call the API to see if it matches existing listings, then unify or flag as needed.
Step 6. Monitor & improve
- Track how many matches you get and review any false positives/negatives.
- Ask real users or your customer‑support team to spot mismatches.
- Retrain your models periodically with fresh data to handle new product lines or changing naming patterns.
With these steps, you can bring the power of AI‑driven product matching into your ecommerce platform, making searches smarter, keeping inventory clean, and helping your customers find exactly what they want.
Final Thoughts: Harness ML for Smarter Product Matching
Product matching powered by machine learning allows for the creation of accurate and relevant product comparisons. With this ML capacity, eCommerce development becomes more consistent and user-focused.
For a seller, it means a higher profit and a clear evaluation of their competitive power. With the help of machine learning algorithms, they prevent situations when a client is presented with an endless list of duplicated products. Sellers provide users with a chance to opt for the most advantageous offer. This pays them off with increased trust and client loyalty.
Also, ML helps to organize identical product offers reasonably in accordance with criteria. It turns e-commerce marketplaces into powerful, intuitive, and convenient spaces for doing business. Businesses get the chance to satisfy the needs of the most demanding clients.
By partnering with experts, you can implement product matching seamlessly, streamlining your catalog, improving search accuracy, and driving sales.
If you want to integrate ML into your eCommerce solutions, contact Forbytes. Our dedicated ML professionals will gladly help you reach your business goals and make the most of machine learning power.

Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?
Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?





