

The opportunities of ecommerce, like buying products or getting services in a few clicks, look very convenient. According to recent estimations, more than 2 billion people conduct purchase and sell operations online. The figure is rapidly growing, with more and more e-commerce trends becoming buyer and customer routine.
Where does effective personalization come in? Solving the tasks of time (when to target), audience (whom to target), and product (which items/services to promote) will make your targeted promotions a success. This time, we will discuss how to make the right product recommendations with the help of recommender systems.
Intro to Recommender Systems
When tailoring a promotion campaign, the following factors should be taken into consideration:
- Develop an accomplished customer profile with the description of their product category preferences, frequency of purchasing, interest in promotions, and premium segment products.
- Identify items/services similarity (multiple relationships).
- Identify relationships between clients and units offered.
- Specify promotion product.
Identifying and targeting particular life events (birthdays, anniversaries, etc.) can take your promotion project to a higher level. And the most important task is the extraction and processing of available data by a company. Businesses are looking for innovative and high-tech solutions to gain customers’ loyalty, and that’s where recommendation systems step in.
Recommender systems are one of the most popular applications of data mining and machine learning in the field of digital business. They analyze customers’ behavior and then offer quantitative and qualitative suggestions of their preferences. The online shop products, web pages, media content, and other web service users can be the objects of recommendations.
Indeed, 40% of app installs on Google Play come from recommendations. Likewise, 60% of watch time on YouTube comes from recommendations as well.

The system can recommend many different things like movies, news, articles, books, job announcements, commercials, etc. Among the most common applications is Netflix’s recommendation engine, which offers visitors a customized webpage. As we search for movies on Netflix, buy goods on Etsy, and look for job offers on LinkedIn, the result we are offered is not just a list of the most popular items. It’s rather a figured-out recommendation conducted according to algorithms that calculate a vast amount of information customers provide with their behavior online. Businesses rely on these calculations. But how do they compute massive information to come up with a final decision that picky customers rely on?
Recommendation Systems Development and Advancement
The development of customization systems as a separate theoretical area started in the mid’s 1990s. It was the first ACM RecSys Conference (Minnesota, 2007) to expand the studies. It’s announced that during the conference held in Seattle, the challenge focus would be on fashion recommendations and the task would be to predict the item that was purchased in the session (given a sequence of item views, the label data for those items, and the label data for all candidate items).
In the early 2000s, Netflix also organized an open competition for the best user rating prediction algorithm. Since then, recommender systems have gained much attention in the IT community. Various open datasets (e.g. MovieLens) contributed to the further development.
Thanks to the advancements in this field, social media platforms such as TikTok and Instagram are now able to suggest content or business advertisements based on user’s preferences. Spotify, a music streaming service, is another example of this technology at work. It anticipates personalized playlists (Discover Weekly, etc.) based on listeners’ previous choices and based on what similar users like.
One more company has made great recommender systems implementation, and this is Amazon. The company examines users’ preferences and interactions to determine the items a customer has earlier purchased or viewed or the items they might have in their baskets or wish lists to offer relevant recommendations to consumers and enhance their experience.
Recommender System Definition
But before diving into different approaches to this technology implementation, let’s outline what a recommendation system is. This is a method of filtering an information stream before suggesting results to a human user. Or, more specifically, this is a technology that aims to predict the “rating” or “preference” a user will give to an item.
Users, items, and interactions between users and items are the elementary fundamentals of recommender systems. This data is managed and interpreted in various types of algorithms.
Types of Recommendation Systems
Primary, there are three types of recommender systems.
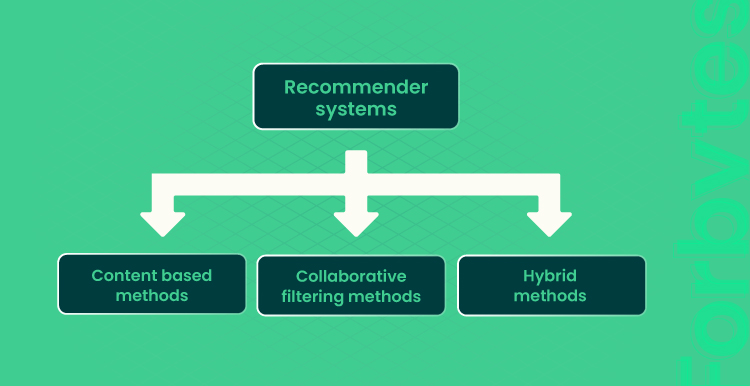
- Collaborative filtering model: recommendation algorithm where recommendations are based on customers’ previous behaviors and decisions made by similar users.
- Content-based recommendation system: a system where a series of discrete, pre-tagged characteristics of an item is used for filtering suggestions.
- Hybrid recommender system: a system that combines collaborative filtering and content-based approaches. These methods are mostly used in large-scale recommender systems and show significant results. Their combination may take two forms: applying two models independently or implementing a single model that unifies both approaches by using prior information about the user and/or item as well as “collaborative” interaction data.
Both users and service providers benefit from these kinds of systems. In addition, the quality and decision-making process also improves thanks to this technology. It’s time to review them in more detail.
Collaborative Filtering Model
Collaborative filtering is considered to be one of the smartest recommender models. To provide serendipitous recommendations, it works on using similarities between users and items simultaneously. This approach makes offers based on the user’s past behaviors and similar decisions made by similar users.
Approaches to solving the problems of the collaborative filtering model can be divided into two major groups:
- A memory/heuristic-based approach is expected to calculate ratings of preferences using a degree of similarity between users or items.
- A model-based approach is the building of a machine-learning model that takes into account latent (hidden) characteristics of users and objects.
The collaborative model allows for building a recommendation system based on a quick and easy solution. But in fact, user moods or product demands/preferences are time-variant data.
Content-Based Filtering
Compared to the collaborative filtering model, the content-based filtering model may include the following benefits:
- No data from other users are required to create recommendations. As a result, it works perfectly for businesses that don’t own a vast pool of customers to collect data. It also works for those with a small number of user interactions in particular categories.
- Recommendations are highly relative and transparent to the users.
- The system provides high-quality early recommendations.
- Content-based recommendation systems are basically easier to implement.
Recommender Systems Evaluation
For any of the above-discussed recommender systems algorithms, performance evaluation is required. It enables one to decide which method fits their use case the best. Here we come up with two basic groups:
- Analysis based on particular metrics;
- Analysis based on user judgment and rate of satisfaction.

Metrics-Based Evaluation
Depending on the model, predicted ratings and matched probabilities are numerical values that the recommender system outputs. We can apply an error measurement metric such as MSE (Mean Square Error) to increase the quality grade of the data produced. This classic approach assumes that the model is performed only on the part of the conducted interactions and tested on another part.
Also, if the recommender system model predicts numerical values, we can apply the classification-like evaluation method. The values can be binarized with a thresholding approach where the values above are positive, and the values below are negative. User-item interaction data is also binary or can be binarized according to the thresholding approach. Therefore, we can check model accuracy on the test interactions not used for performance.
It may happen that the recommender system doesn’t predict numeric values and results in a list of suggestions based on the k-Nearest-Neighbours (kNN) classification method (user-user or item-item-based recommendations). In such cases, we can simply calculate the proportion of recommended items that respond to the user preferences. Then we’ll test only datasets with user feedback and ignore those suggested items that users didn’t interact with.
Human-Based Evaluation
Providing reliable recommendations is not the only objective when deploying the recommender system. More often, we also expect the generated recommendations to be diverse and explainable.
What we don’t want to achieve is some kind of restrictions or limitations for the users. And when we talk about the diversity of suggestions created by the selected model (collaborative filtering), we commonly use the term “serendipity.” This notion denotes unexpectedness multiplied by relevance (or cases when a user may be stuck in a limited area). So, the serendipity rate can’t be too low, which would mean the recommended items are too similar and create limitations of choice. Hence, the high serendipity would mean that not all user preferences are taken into account, and the list of recommendations is somewhat “blurred.”
Another criterion of the recommender system’s success can be user confidence. A short description of the recommendation algorithm can be a good tool for evaluating this metric. For example: “People who bought this item also liked this one”, “You watched this movie, you may be interested in watching this one too”, etc.
In practice, diversity and explainability can be very challenging to check out. Also, we find it complicated to evaluate the recommendation that is not added to the testing dataset quality. Here arises a question: How can we be sure that our suggestions are correct and relevant before implementing them to real customers? These are the reasons that explain the temptation to test customization algorithms under “real conditions.”
Buying a product, watching some video, applying for a position announced — these are the examples of actions expected from customers that our model has to generate. For this purpose, we can apply the A/B testing approach right after the product launch. Another solution to this task could be testing on the so-called focus group of final users. However, you should be confident in the model to apply these methods.
Team Skills Essential for Implementing Recommender Systems
Implementing a recommender system is a standard machine learning task. Besides being good at statistical analysis tools, the team of developers should be familiar with tools and frameworks that provide an infrastructure for building recommendation engines. Depending on your accomplishment task, these may include programming languages like Python and Scala, frameworks, and libraries like Neo4, LensKit, or Hadoop/Spark MLlib, etc.
And if you are looking for someone to help you implement ML into your eCommerce platform, contact Forbytes. Our dedicated professionals with the appropriate expertise will eagerly help you reach your business goals.
Final Word
The recommendation systems have changed the approach to decision-making. They have proved to be an advantage for users to cope with the vast amount of dynamically generated information: buyers spend less time searching online. Meanwhile, sellers use this technology to increase sales and build brand loyalty.
As for the business impact, recommender systems help companies increase their ROI by customizing content based on user preferences. Various techniques of recommendation are successfully deployed in the commercial environment.
The main takeaways of this article are:
- Recommender systems work with a large quantity of information provided by users and other factors related to user preferences and interests;
- There are three types of recommender systems: collaborative filtering (based on ratings only); content-based (based on the item and/or user declarative features); hybrid (mix several models; based on declarative and latent features);
- There are different recommender systems evaluation metrics and different types of testing.
When choosing the right recommender algorithm, companies should make decisions based on multiple factors: accuracy, complexity, business impact, and more. They also have to be realistic about the company’s resources available (number of engineers, software/hardware costs, etc.).
And speaking of eCommerce, you can also sneak a peek at our blog on data-driven decision-making to continue the ongoing process of cultivating data-driven values in your team.

Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?
Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?





