Data labeling is a critical part of training machine learning models. In this blog post, we’ll share tips and best practices for effectively labeling data for ML. By following these guidelines, you can ensure that your models are trained on high-quality data that will lead to better results.
What Is Data Labeling and Why Is It Important for ML?
Data labeling is a form of data annotation that involves identifying and categorizing data objects by assigning labels to each data object, such as recognition or classification tags. These data labels are often used to identify and classify data for image recognition and natural language processing tasks, helping determine what specific data represents for further analysis.
Data labeling is a critical process in the development of ML models. By providing data with explicit labels to train and test ML algorithms, data labeling assists ML initiatives in improving accuracy levels and achieving tremendous success overall. Data sets are “marked up” with key categories, providing an easy way to organize data from the unstructured data format it often comes in. This properly categorized data allows areas of interest to be quickly identified, and precise results can be drawn from targeted data sets.
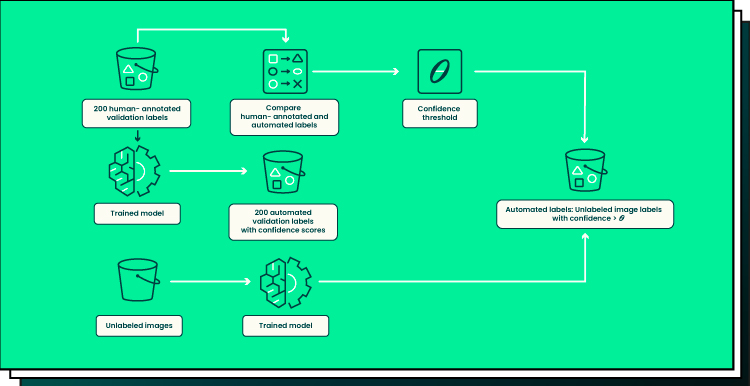
Since it enables machines to learn from examples, data labeling lays the foundation for organizations to gain insights from their data-driven resources, leading to more efficient decision-making capabilities.
Not only does it contribute to better model performance, but it also helps save time during the development process by reducing tedious processes that are usually done manually without accurately labeled data.
Importance of Data Labeling Accuracy
Accurate data labeling is essential for successfully implementing ML models, as it is pivotal to the training data’s quality with which ML models learn. Inaccurately labeled data has a significant impact on the performance of ML models by distorting the output. It can distort reporting results and thus skew decisions made as a result of model predictions. For data scientists, data labeling processes must be both accurate and efficient – taking too long to label data can reduce its applicability and make it impossible to incorporate data into predictive systems on time.
To ensure the development of accurate and reliable algorithms, data needs to undergo a rigorous labeling process that results in data of high quality. Hence, the data pre-processing stage can make a significant difference in the overall performance and effectiveness of data-driven projects. Therefore, developers must ensure that they have all the tools necessary to reduce manual data labeling operations while maintaining a high degree of accuracy in the process.
Data Labeling Strategies
Selecting an appropriate data labeling strategy will depend on various factors such as timing, budget constraints, desired level of accuracy, etc., making it essential to weigh all options before deciding. In addition, when choosing a strategy, organizations should consider their specific objectives and any challenges they may face when implementing their preferred approach.
Let’s discuss the most common data labeling techniques.
Manual Labeling
This is the most common form of data labeling. It involves assigning labels to a dataset by hand, usually by an expert. This strategy requires time and effort to accurately annotate data points with meta-tags to ensure accuracy when training machine learning models later. However, it yields reliable and accurate results. Therefore, it is often used when dealing with large datasets or when additional context is required to assign labels.
Crowdsourcing
This method relies on hiring a large group of people to label datasets. This technique is ideal for tagging images or videos in which each frame has a unique label or description. Though it is cost-effective and can be completed quickly, it comes with the potential downside of inconsistent labels due to varying levels of expertise among those performing the labeling tasks.
Automated Data Labeling
Automated data labeling techniques involve leveraging existing technology, such as NLP, computer vision (CV) algorithms, AutoML, and supervised machine learning models, to generate labels for unstructured datasets automatically. In addition, these techniques involve using algorithms that can automatically identify objects or text without any human intervention for labeling purposes.
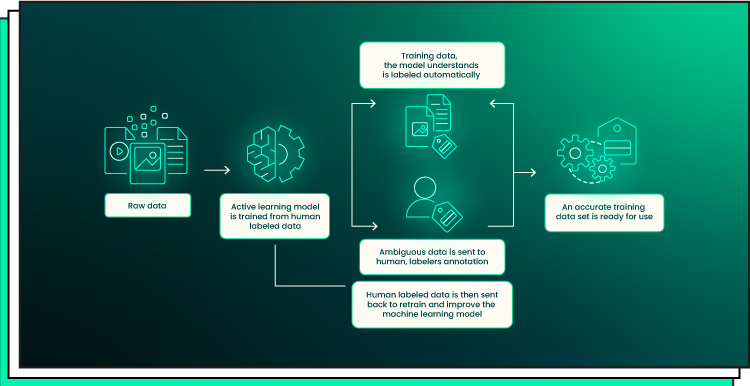
Comparison of Different Data Labeling Strategies
Overall, each of these methods of data labeling has its unique strengths and weaknesses when applied to machine learning projects. Depending on the type of project, one strategy may be more suitable than another based on factors such as required accuracy level or available human resources and budget constraints. Ultimately, selecting the right approach will depend heavily on the specific needs of each machine-learning task at hand.
Let’s discuss the pros and cons of the three most popular techniques.
Manual Labeling Pros and Cons
The pros of manual data labeling for machine learning include the following:
- Accuracy. Manual data labeling often produces highly accurate results, as skilled labelers can provide precise and consistent labels for each item.
- Flexibility. With manual labeling, data scientists can label items with nearly any description or attribute, allowing them to create extremely high-quality datasets for various ML applications.
- Scalability. With an experienced team of labelers in place, virtually any amount of labels can be generated quickly, with quality assurance checks built-in throughout the process as necessary.
It also has drawbacks, such as:
- Speed & efficiency. Manually labeling items can be time-consuming compared to automated solutions, resulting in faster processing and slower production speeds.
- Subjectivity & bias. Human input inherently introduces subjectivity into the process, which can lead to inconsistencies in how different individuals label datasets.
Crowdsourcing Pros and Cons
As for the crowdsourcing method, its benefits include the following:
- Accessibility. This method enables organizations to tap into a global talent pool that would otherwise not be available due to geographical boundaries or other factors.
- Efficiency. Since it eliminates manual labor, organizations can reduce costs and improve productivity by reducing time spent on manual labeling tasks.
- Speed. It is ideal for use in rapidly changing environments where speed is essential and manual intervention is not an option due to a lack of resources or time constraints.
It also has its cons, such as
- Quality control. If users are unfamiliar with the characteristics of certain types of images that need to be labeled properly, they may end up providing inaccurate labels, which could lead to inaccurate results when used in production models and applications down the road.
- Security concerns. As with any online activity involving large numbers of people from around the world accessing personal or proprietary company information, security concerns are always present when utilizing crowdsourced data labeling services. Therefore, this approach may require additional solutions designed specifically for fraud detection in ML.
- Lack of standardization. Task requirements, parameters, metrics, etc., must be carefully tailored toward each project to yield meaningful results. This leads to increased complexity within such initiatives, adding extra time & investment costs associated with each new project.
- Time constraints. Finally, another limitation faced when utilizing crowdsourcing strategies lies within time constraints imposed by users themselves.
Automated Labeling Pros and Cons
Finally, automated labeling yields the following benefits:
- Increased accuracy. By leveraging algorithms and automation processes, automated labeling can provide more accurate data than manual labeling, reducing errors and increasing the overall accuracy of the data used in machine learning projects.
- Increased efficiency. Automation processes mean labels can be generated much faster than manual labeling.
- Optimizes resources. Automated labeling can help optimize resources by providing a way to quickly generate labels from large data sets with minimal effort required from human labelers, resulting in time savings and increased productivity.
- Improved quality control. Automated systems can better identify and address errors or inconsistencies in the data without requiring additional resources or input from human labelers.
The cons of this method include
- Dependency on algorithms & technology. Automated labeling solutions depend on algorithms and technology that may not always be 100% accurate or reliable.
- Complexity & technical challenges. Implementing an automated labeling solution can be very complex due to the technical nature of setting up such a system, which requires advanced technical knowledge.
- Lack of human oversight/intervention. Since automated labels are generated without any human oversight or intervention, there may be instances where errors go unnoticed due to the lack of quality assurance measures put in place.
Best Practices for Data Labeling
So far, we’ve learned that data labeling is a critical step in successful ML operations. However, accuracy can vary significantly depending on the data labeling strategy and team management. To maximize accuracy in data labeling, organizations should consider the following advice and tips:
Selecting an Appropriate Data Labeling Strategy
This can range from machine learning-based methods such as supervised or unsupervised learning, depending on the task. Additionally, consideration should also be given to using domain expertise and crowd-sourcing techniques. Organizations should determine which data labeling strategy is most appropriate for their needs by considering the available resources, types of data to be labeled, and desired outcomes of the project. Organizations should also determine whether supervised or unsupervised algorithms will be used and consider any associated costs or risks involved with each option.
Monitoring Quality
Once a data labeling strategy has been selected, it is vital to monitor the quality of labeled data by regularly performing accuracy checks and providing ongoing feedback for developers and teams working on the project. It is also beneficial to periodically check for consistency among labels (e.g., different labelers assigning the same label for a given object). Maintaining high-quality results requires ongoing monitoring and evaluation of labeled data. Organizations should set up quality assurance processes and review procedures to ensure all labels are accurate, consistent, and compliant with applicable standards and regulations.
Managing Data Labeling Teams
It is essential to ensure that all team members have clear instructions about the tasks they need to do and what constitutes an acceptable output. Furthermore, setting up processes and protocols for communicating with the team members will help ensure they are aware of any changes or updates that may affect their work. Organizations should define roles for each member based on their expertise and assign tasks accordingly. Regular progress reports should also be provided so managers can track progress toward established goals in real time while identifying potential issues before they become problems.
Final Word
By understanding the main types, best practices, and common pitfalls of data labeling, developers can ensure their ML-based projects are as accurate and reliable as possible. Getting it right requires understanding applicable rules and regulations, engaging professional labelers if necessary, having a careful QA process to ensure accuracy, and investing in the latest data labeling tools. While creating effective data labeling strategies can be challenging, taking the time to do so properly is essential to minimizing bias and actively future-proofing your models.
Are you building an ML project and need extra help in the process? Forbytes can help. Your operations, procedures, and problems will be examined by our ML consultants. We will guide you through the digital environment and recommend the solutions to incorporate to make it more customer-focused and successful.

Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?
Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?