Artificial intelligence (AI) unlocks new ways for the healthcare industry to improve the accuracy and speed of diagnosis, treatment, and research. Much of this success depends heavily on the availability of large-scale medical datasets to feed AI algorithms for optimal performance. Leveraging data science has opened many opportunities in fields such as imaging analysis, drug discovery/identification, and predictive analytics – transforming how healthcare works today.
This blog post explores why medical datasets are essential to support AI applications in healthcare, their key characteristics that make them different from other significant data sources, and what makes them so effective when used with ML models.
Introduction to Transforming Healthcare Through AI
ML is already making waves in the healthcare industry. AI-powered imaging tools can detect anomalies more accurately than radiologists can – allowing doctors to diagnose conditions faster and more precisely. ML models are being used to diagnose cancer types earlier and increase the efficiency of drug discovery processes. The development of AI systems can also help facilitate personalized treatments by considering an individual’s lifestyle choices, genetic information, and current health status to develop tailored care plans.
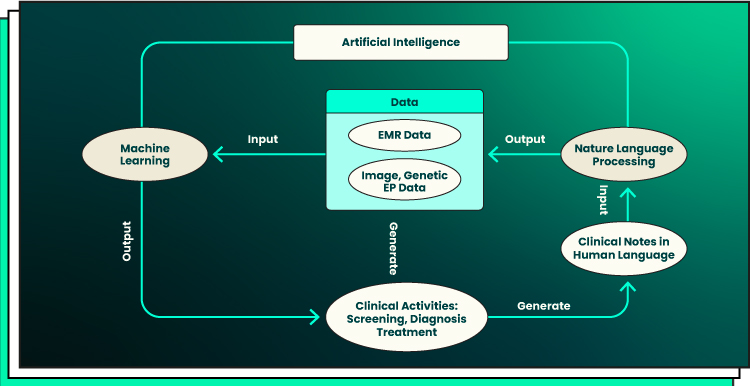
The road map from clinical data production, through NLP data enrichment and ML data analysis, to clinical decision-making is shown in the graphic below. The clinical actions are where the route map begins and concludes. Notwithstanding how potent AI approaches may be, their application must ultimately support clinical practice and be driven by clinical problems.
AI-driven medical technologies can help medical staff better diagnose diseases with greater accuracy, identify appropriate therapies for individual patients, provide personalized healthcare services via chatbots, predict health risks more accurately, and even detect early signs of disease or complications. AI algorithms can also be leveraged to analyze large volumes of patient data quickly to inform long-term treatment strategies.
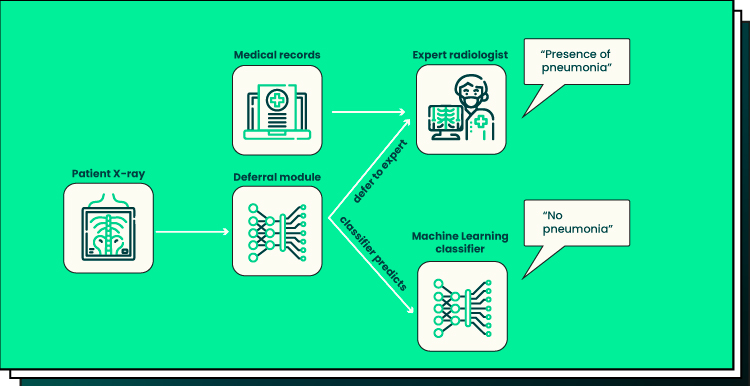
A new AI diagnostic system has been created by ML researchers at MIT’s Computer Science and Artificial Intelligence Lab, or CSAIL. The system, according to the researchers, can make a diagnosis or decision based on digital findings or, more importantly, recognize its limitations and consult a carbon-based lifeform that might be able to make a more informed decision.
AI has implications beyond just diagnosing diseases — it also allows for new approaches to preventive care. ML-based technology is helping healthcare professionals understand how environments and behaviors influence health, providing healthcare providers with valuable insights on how to treat existing conditions or anticipate future ones. Additionally, automated ML algorithms can effectively initiate early interventions for at-risk patients before symptoms arise, drastically increasing the chances of successful treatment outcomes while decreasing costs associated with delays in diagnosis or inaccurate predictions.
By leveraging digital data sources like electronic medical records (EMRs), wearables, and mobile health apps, AI systems are proving incredibly useful in helping practitioners make better decisions about treatments or interventions faster than ever before. In addition to improving diagnosis accuracy, leveraging digital data sources for predictive analytics purposes has enabled healthcare organizations to create population health management programs that target high-need populations to reduce readmission rates or preventative screening gaps hence improving the overall quality of care.
The Importance of Medical Datasets
Medical datasets are playing an increasingly critical role in the development of Artificial Intelligence (AI) and ML models. In particular, these datasets are essential for training ML algorithms to predict health outcomes based on patient data accurately. Data quality is paramount when using medical datasets in AI and ML models. Poor-quality data can lead to inaccurate results, wrong diagnoses, and poorer patient care. The accuracy of predictive analytics can be improved by robust data collection practices that ensure that all relevant information is captured accurately and consistently.
Privacy is another essential concern regarding medical datasets and AI/ML models. Patient records contain sensitive personal data, including names, addresses, social security numbers, and medical histories, which must be safeguarded according to ethical principles and applicable laws. AI/ML algorithms should also be designed with privacy protection features built into them. For example, masking unneeded or sensitive information or preventing access by unauthorized personnel.
Finally, ethical considerations must be considered when developing AI/ML models from medical datasets. Advances in technology allow us to do things we were unable to do before. However, this should not come at the expense of patients’ rights or privacy being compromised. Ethics boards need to review any proposed use of a medical dataset before it goes into production to protect the interests of both patients and providers alike. Furthermore, guidelines should be established for the responsible use of medical datasets, such as ensuring that all data is anonymized before release and that only approved personnel can access it.
Best Practices for Medical Datasets
High-quality medical datasets are essential for the development of effective ML models. While it is possible to create a usable dataset from existing sources, this approach often yields substandard performance and cannot effectively address specific research questions. To ensure that datasets used for medical research are of high quality, the following guidelines must be taken into account:
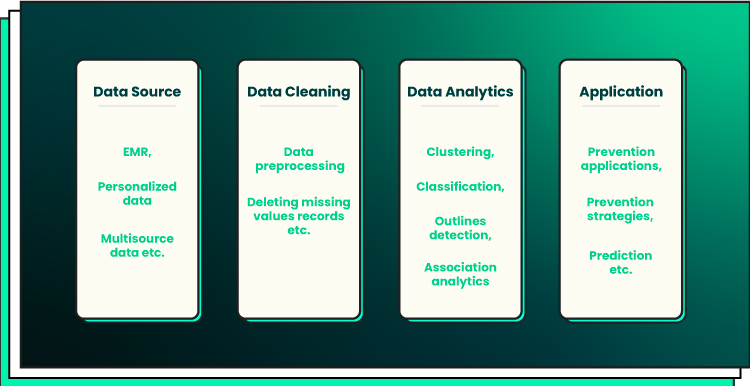
- Data collection. When collecting data for a medical dataset, it is important to consider the various sources available. Medical records, imaging studies, laboratory test results, and patient surveys are all common data sources. However, it is critical to ensure that any collected data is accurate and reliable before using it in a dataset. Automated methods should also be employed when possible to reduce human error. For instance, NLP techniques can be used to extract information from unstructured text sources such as physician notes or patient surveys. Additionally, databases should be designed with scalability in mind so that they can accommodate additional data as needed without compromising performance or accuracy.
- Preprocessing. After collecting the necessary data for a medical dataset, it must be preprocessed prior to analysis or use in an ML model. Preprocessing typically involves cleaning up the raw data by removing incorrect values or filling in missing values with appropriate estimates. Feature engineering may also be done at this stage: for example, combining two separate measurements into one feature or extracting only certain types of information from larger datasets such as images or text documents. Finally, normalization should be used to ensure that all values are within an acceptable range for use in an ML model. Otherwise, the model may produce inaccurate results due to skewed input features.
- Annotation. To enable automated analysis of medical datasets by ML models (e.g., deep neural networks), manual annotation must often be performed on the dataset before training begins. Generally speaking, this involves labeling each instance (e.g., an individual image) according to its content (e.g., healthy vs diseased). When annotating large datasets with multiple labels (e.g., organ-specific diseases), specialized tools made specifically for this task should preferably be employed since they can significantly reduce time spent on manual annotation while still yielding accurate results due to their sophisticated algorithms and dynamic interfaces, which allow users to quickly review annotations made by others before finalizing them themselves if needed. Additionally, professional annotators — experts with niche knowledge about particular areas — should always be consulted when dealing with complex tasks involving subject matter expertise. Expert-level annotation ensures that even small details relevant to medical diagnoses are accurately captured by the ML model during training.
Additionally, quality control is key when creating a medical dataset since inaccurate results could lead to dangerous outcomes. Therefore, it would be wise to double-check any results obtained from datasets before making any inferences or decisions based on them.
Challenges and Limitations
Using medical datasets for AI and ML applications is a powerful way for healthcare professionals and administrators to gain insight into patient health, treatment outcomes, and other critical clinical metrics. However, while the potential benefits of leveraging such data are clear, some serious challenges and limitations must be considered if these technologies are to be used responsibly.
Data privacy and security are especially important aspects when using medical datasets. Such data typically contain confidential information about the patient’s health status, treatments received, lifestyle factors, etc., and sensitive personal details such as addresses and contact numbers. The risk of unauthorized access to this information by nefarious third parties or malicious insiders cannot be overstated. Failure to secure these databases could result in significant penalties under applicable laws such as the Health Insurance Portability and Accountability Act (HIPAA) or the General Data Protection Regulation (GDPR). Organizations should therefore implement robust security protocols to protect their medical datasets from unauthorized access. This includes encrypting patient records at rest or in transit, robust authentication processes for authorized users, regular patching of system vulnerabilities, and regular monitoring of suspicious activities.
Along with safeguarding data privacy and security, it is also necessary to consider ethical implications associated with the use of medical datasets in AI and ML initiatives. Healthcare organizations must take steps to ensure that any insights gleaned from these datasets do not negatively impact patients by creating discriminatory outcomes based on factors such as race or gender. Doing so would go against many ethical codes of conduct established by professional bodies such as the American Medical Association (AMA) or The World Medical Association (WMA). To prevent such biases from forming in their systems, companies should use rigorous testing methods on their data models prior to deployment to identify any potential sources of discrimination early on and address them accordingly.
Another challenge faced when using medical datasets with AI and ML is bias. This occurs when human-authored algorithms reflect an individual’s unconscious biases instead of making objective decisions based on available evidence. Biases can be seen in datasets generated from specific demographic categories, meaning that training systems may be more likely to draw certain conclusions from these demographics than from other groups due to pre-existing biases.
Furthermore, collecting medical data presents issues with consent. Individuals should always be made aware of how their data will be used and should provide explicit consent before it can be collected. It is also important to consider storage protocols for data once collected. If stored on public cloud services, the risk of unauthorized access increases substantially compared to private facilities or local repositories on personal computers.
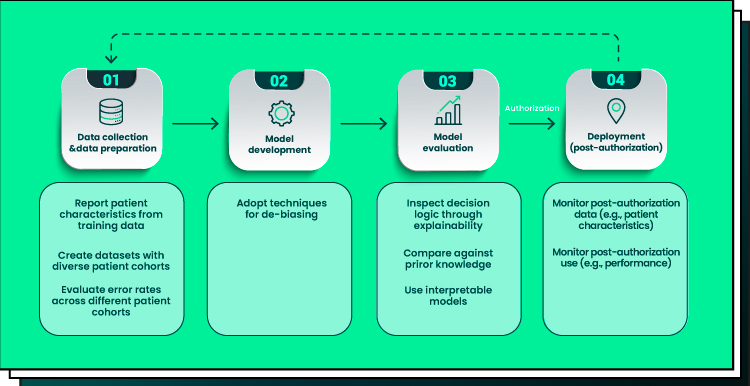
Finally, organizations must avoid making decisions based solely on insights gained from AI/ML models fed with medical datasets. Experts should always be involved in reviewing output results before any decisions are made. This helps ensure that results are not simply computer-generated ‘guesses’ but rather ones informed by human intelligence alongside analysis of available evidence, which will likely lead to better decision-making overall. Doing so also helps reduce the risk of introducing unintentional bias into the model due to errors related to incomplete or incorrect data inputs, which could have a detrimental impact on patient outcomes if left unchecked.
Future of Medical Datasets
The potential applications of medical datasets are almost limitless, with possibilities ranging from predicting disease onset and diagnosing illnesses to developing better treatments. Additionally, they can be used to track patient outcomes over time, allowing for early detection of health issues and improved treatment efficacy. With the help of ML and AI, doctors can analyze large amounts of data quickly, leading to faster diagnoses and better treatments for patients.
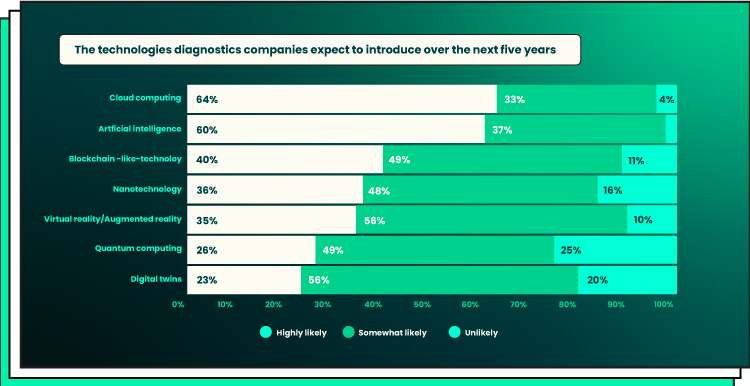
The rapid availability and ever-expanding volume of medical datasets also offer hope for drug discovery research – promising faster paths toward finding new treatments for some of the world’s most challenging diseases. By training AI algorithms on large amounts of biological data, pharmaceutical companies can identify promising new drugs much more quickly than traditional methods allow. This will open up opportunities for innovative clinical trials that leverage real-world evidence instead of relying on artificial scenarios created in a lab environment.
A future where medicine is personalized, predictive, preventative, and participatory is what Deloitte envisions for the health ecosystem with the use of AI and other cutting-edge technologies using data from numerous sources.
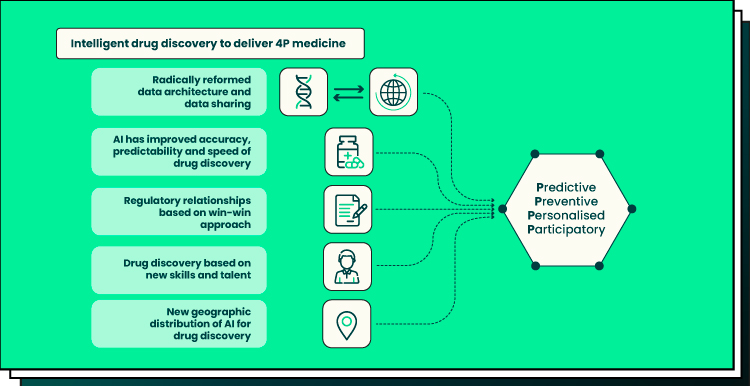
Technologies such as natural language processing (NLP) are helping to further enhance medical datasets by analyzing unstructured data sources such as patient notes and medical reports. NLP can extract critical information from these sources to build more accurate models for predicting outcomes. In addition, AI models are now also being used for decision support for personalized treatments, providing clinicians with specialized advice about individual cases.
To sum it up, we’ll likely see tremendous progress from medical datasets over the next few years – accelerating breakthrough discoveries across many different fields while improving healthcare services significantly along the way. Leveraging advances in AI and ML alongside emerging technologies such as NLP will no doubt play a pivotal role in driving this transformation forward, unlocking unprecedented levels of insights into how we diagnose, treat, and prevent illness worldwide.
Final Word
Datasets are a critical component for the success of ML systems, and their lack is a major challenge facing AI in healthcare. However, with a dedicated effort from both government and private organizations, datasets can be expanded to include valuable information as well as increase data security compliance. Such initiatives must be undertaken to maximize the transformative potential of ML in healthcare.
Forbytes has developed rich experience with clients across multiple sectors, not just in medicine but also in banking, insurance, education, and retail. If you need assistance managing the complexities associated with healthcare networks, reach out to us. Together we can turn vision into reality and create a future where AI will work effectively in tandem with existing medical professionals to help everybody lead their lives healthier and happier.

Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?
Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?