

In recent years, artificial intelligence (AI) and machine learning (ML) have seen phenomenal advances. However, while ML algorithms are becoming more and more effective at solving complex tasks, they come with an intricate task: determining how they reach their results. With these advanced models often being impenetrable “black boxes,” understanding how a given AI makes its decisions is paramount for responsible deployment.
In this blog post, we will explore the concept of interpretability in ML — what it is and why it helps to better understand machines. Hereafter, we will examine some fundamental approaches that help bridge the gap between human understanding and algorithmic inference.
Introduction to Machine Learning Interpretability
Deep neural networks (DNNs), a robust ML algorithm, have recently acquired the ability to harvest unusually vast volumes of training data. This allowed the technology to reach record achievements in numerous study disciplines. However, DNNs are sometimes considered “black box” methods since it is challenging to intuitively and statistically comprehend the outcome of their inference, i.e., for each unique piece of novel input data, how the trained DNN model came to a specific response. Because of the potential adverse effects of this lack of transparency, such as in medical applications, research on interpretable AI has recently gained more interest.
ML interpretability is a term that refers to the ability of an ML model to explain its decision-making process. It plays a vital role in ML applications because it helps understand how the model works and identify potential issues. Knowing whether or not to trust an ML model is critical. Interpretability helps ensure that the data used in training the model was applied correctly and that the assumptions made by the model are correct.
Take a look at a simple neural network with two hidden layers:
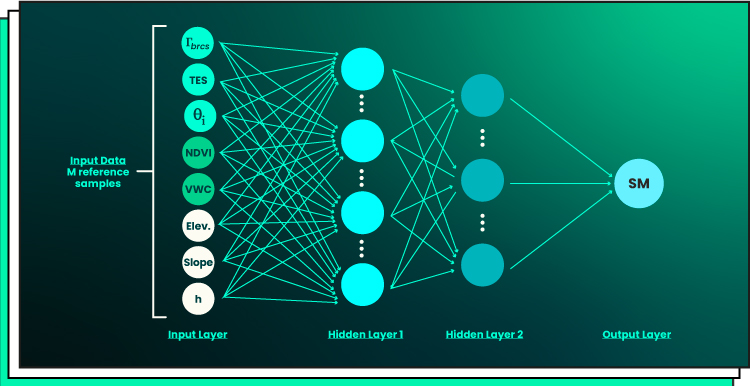
Interpretable models provide detailed explanations for their decisions, such as which features are most important for predicting results. This can help data scientists better understand when and why a model fails, allowing them to identify and fix any issues more quickly. Additionally, interpretability can help identify any biases in the training data being used, thereby helping organizations avoid ethical pitfalls like algorithmic discrimination or privacy violations.
Interpretability techniques vary from simple techniques like rule-based models, which provide explicit rules for modeling decisions, to complex processes such as feature importance analysis identifying factors affecting prediction outcomes. In addition, natural language processing (NLP) methods are available that allow machines to generate explanations using human-readable text rather than numerical values or equations. Moreover, there are emerging research projects exploring interactive visualization tools that allow users to explore how different variables interact to gain further insight into the inner workings of their ML models.
ML Interpretability vs. Explainability
The critical difference between ML interpretability and ML explainability is that interpretability focuses on how well the model can accurately describe a cause-effect relationship. In contrast, explainability focuses on revealing the underlying parameters within a deep net.
Interpretability refers to the degree to which humans can readily understand an algorithm’s output. It is essentially about quantifying ML models’ “interpretable” quality so that users can get some insight into their inner workings and make better decisions based on the results. Commonly used metrics for evaluating interpretable models include feature importance scores, visualization techniques such as decision trees, and descriptive statistics.
In contrast, explainability examines how well data scientists can understand and uncover information from DNNs. This includes understanding what influences and affects certain decisions made by the model. For example, explainable AI typically seeks to discover why a particular decision was made by providing evidence for its reasoning in addition to answers, such as generating feature importance scores or visualizing hidden layers of neural networks. Explainability also highlights potential biases in data sets or algorithms that could lead to inaccurate predictions or flawed conclusions.
Overview of Interpretability Methods
Interpreting ML models is a complex yet vital task to gain insights and develop strategies. Feature importance, partial dependence plots, and decision trees are three of the most popular methods for interpreting the models.
Regarding feature importance, it assesses each feature’s relative impact on predictions. It can help identify which features are more important than others and, therefore, can be used for data preprocessing or generating new features that could improve a model’s performance. Typically, feature importance is computed using a metric (e.g., Gini importance) that measures how much each feature contributes to the prediction accuracy of a model. This information can then be used to inform decisions about which features should be kept or removed before training a model.
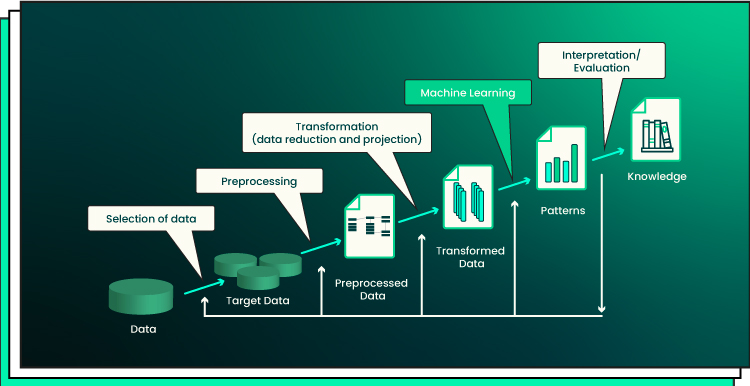
Note: While analyzing the entire data science process for transforming data into knowledge, it’s crucial to note that there is no scientific evidence for a general tradeoff between accuracy and interpretability. When dealing with actual issues, interpretability is helpful for troubleshooting, which improves accuracy rather than reduces it.
Take a look at the ML knowledge discovery process:
Partial dependence plots (PDPs) are also commonly used for model interpretation. PDPs provide insight into the relationship between input features and predictions by showing how the predictions vary as one or two input features change while holding all other inputs constant. They help understand how much of an effect each feature has on predicting outcomes — both individually and when combined with other features — and consequently, allow researchers to make better-informed decisions about the best ways to use predictive models.
Lastly, decision trees are another valuable tool for interpreting ML models as they show how changes in input variables affect predicted outcomes intuitively. In addition to providing insight into feature relationships, decision trees also help identify potential areas where improvements need to be made. They highlight weak spots in predictive models with low accuracy scores on specific subsets of data points or regions where overfitting may have occurred due to too few samples being available for training purposes.
These methods provide powerful visualizations that help data scientists better understand relationships between different attributes and outcomes to create more accurate ML models with higher predictive power. By taking advantage of these techniques, it is possible to maximize the ability to make informed decisions about data-driven applications. It’s also possible to conduct detailed analyses of models’ outputs and performance metrics before deploying them in production environments.
Best Practices for Interpretability
Improving the interpretability of ML models requires careful consideration when selecting a suitable algorithm, preparing data correctly for modeling purposes, and validating models regularly for bias and changes in performance over time. A thorough review at each step will help ensure high levels of accuracy and explainability that enable practitioners to gain insights into each prediction based on certain features or conditions in its environment.
To enhance the ML models’ interpretability, consider the following guidelines:
Select the model
When selecting a model, it is essential to consider how well it can be interpreted. Highly complex models may offer better predictive performance but lack explainability. It is critical to assess whether an interpretable model can provide an acceptable level of accuracy or if more complexity is necessary. Additionally, some models come with built-in feature importance measures that can be useful in understanding which features have contributed to the prediction outcomes.
Prepare data
Data preparation is crucial in ensuring that ML models are interpretable. Data should be formatted correctly, cleaned thoroughly, and transformed appropriately so the model can effectively learn from it. This means eliminating errors, outliers, and missing values, as these can significantly affect the accuracy of predictions generated by the model. Additionally, features should be encoded correctly to maximize their predictive power while avoiding overfitting due to redundant inputs. Feature engineering techniques like one-hot encoding and dimensionality reduction, such as principal component analysis (PCA), may also help improve the interpretability of a given model.
Validate the model
Finally, it is critical to validate machine learning models before being used in production environments. This includes testing for bias and ensuring the fairness of predictions across different groups in the population being modeled. Additionally, model performance should be monitored regularly for any changes in accuracy or predictiveness over time, as this could indicate concept drift or other changes that might affect the interpretation of results generated by the model.
Challenges and Limitations
Interpretability in ML is an active research area, and several challenges are associated with it. One of the main ones is the trade-off between accuracy and interpretability. Complex models tend to have higher accuracy, but they are also more difficult to interpret as they have many parameters that can interact with each other in complex ways. This means that it may not be possible to completely understand what features or values influence a prediction for a given model, making it difficult to explain why the model produces a specific output. Moreover, this lack of interpretability can make it challenging for stakeholders to trust the results produced by such models.
Another challenge is the difficulty in interpreting complex models. As previously mentioned, complex models have many parameters that interact with each other in intricate ways. As a result, there may be no clear way of understanding what factors contribute most to the final prediction made by these models. Additionally, some of these parameters may represent non-linear combinations of input variables, making them even harder to interpret. Furthermore, these interactions between different factors or variables may be too subtle for human interpretation, making them even more challenging to comprehend.
Interpretability can also be affected by different biases present within data sets used by ML algorithms. For example, algorithms tend to learn patterns from training data. If these datasets contain biases or errors, the model could make erroneous predictions, which could create difficulties when attempting to interpret its output. As such, careful consideration should be taken when constructing datasets for use with ML algorithms. Any potential issues should be addressed prior to their use to ensure accurate interpretations of these systems.
Future of Interpretability
With the increased complexity of ML interpretability models, it is becoming vital for scientists and engineers to understand how their models work. To achieve this goal, several emerging trends are being used. One of those is Explainable AI (XAI) – an approach that attempts to explain the behavior of a model by attributing specific decisions made by the model to certain input features. This allows us to gain insight into what causes a model’s output and helps us better interpret why it made certain decisions.
Another emerging trend in interpretability is referred to as Model Extraction. Model extraction attempts to extract existing knowledge from complex ML models so that humans can make use of it without having to understand how the underlying model works. This approach has been successfully used in NLP, where existing knowledge can be extracted from DL algorithms trained for tasks such as sentiment analysis or text generation.
Finally, another method being explored for improving interpretability is Active Learning, which involves incrementally training models on new data points while collecting feedback from users who assess the accuracy of each new data point before feeding them back into the system. This approach allows researchers to train complex models without compromising accuracy and understand input data better over time while collecting user feedback about its accuracy.
Final Word
The wide array of techniques available for interpretability in AI can help demystify ML complexity, ensure better decision-making processes, and deploy meaningful predictions. Already, businesses are beginning to leverage these techniques to gain insight into their data and leverage the predictive power of AI accordingly. For organizations with difficulty making sense of this technology and wanting to increase understanding further, we at Forbytes can assist by leveraging our expertise in this area.
From deploying superior AI models to assessing complex decisions and promoting organizational transparency, Forbytes will help you get the most out of your ML investments.
Reach out today to learn more about how Forbytes can help bring your company into the age of AI with confidence. Contact us.

Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?
Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?





