More and more clients come to us with data management issues. The reasons differ. Some want consistent data to avoid mistakes and losses. Others need better reporting to make decisions with confidence. Many are simply stuck with data scattered across systems and formats that don’t match.
What does this tell us? Data is no longer just stored information. It’s a business tool and a source of insights that support steady growth.
If you’re here, you likely face the same issue: you have plenty of data, but you’re not sure how to turn it into value. The truth is, before you can use your datasets, you need to prepare them.
That’s where the data ingestion process is relevant. It’s the base of any solid big data strategy. It helps you clean, organize, and store data so it’s ready for analysis.
Statista reports that the volume of data created, captured, and consumed worldwide reached 120 zettabytes in 2023. By 2028, this number is expected to climb to 181 zettabytes. With growth like this, knowing how to handle your data is no longer optional. Data ingestion is one way to do it.
In this article, we’ll explain what data ingestion is and outline its benefits and challenges. Let’s get started.

What Is Data Ingestion?
Data ingestion is the process of collecting data from different sources and bringing it into one place. The goal is simple: make the data clean, consistent, and easy to access. Once the ingested data is stored in a central repository, you can process and analyze it without dealing with scattered files.
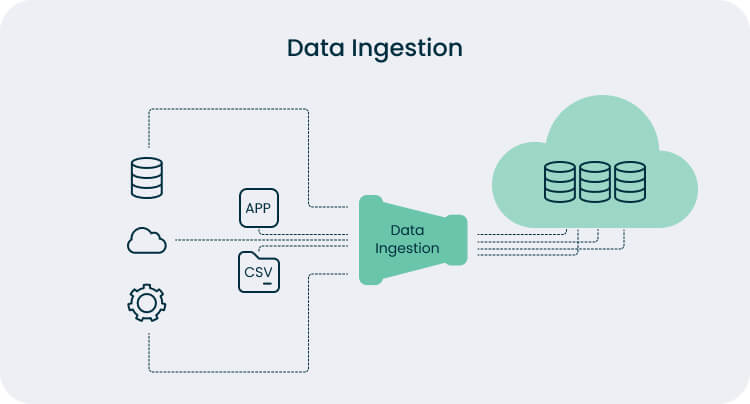
Take big data in retail as an example. E-commerce owners gather data from online orders, in-store purchases, loyalty programs, and social media. That’s a lot to handle, right? Data ingestion brings it all together in one place. Once collected, companies can spot buying patterns, manage inventory more efficiently, and create promotions that reach the right customers.
By pulling all your data into a cloud-based warehouse or data lake, you can organize it, analyze it, and turn it into insights you can actually use. Data ingestion lets you work with quality data.
Why Data Ingestion Matters for Your Business
Now that you know what data ingestion is, it’s time to see why it matters. Properly ingested data is consistent, organized, and easy to access. More importantly, it delivers real value, helping your business make smarter decisions, spot patterns, and act with confidence. So, how can your business benefit from it?
Real-time access to your data
Storing data in the cloud makes it easy and secure to access large datasets whenever you need them. A cloud-based data pipeline for ingestion removes the limits of physical storage and lets your business use data anytime, anywhere.
For example, at Forbytes, we helped NoWaste, a leading European logistics company, centralize data from multiple warehouses and systems, including WMS, HR, and ERP. With a cloud-based data lakehouse, their teams can access consistent, up-to-date information across the organization. Managers can track inventory and monitor operations in real time, without being tied to a particular system.
Better data quality
When organizations merge information from multiple sources, they can spot inconsistencies, errors, and gaps in their data. This makes it possible to correct mistakes before they affect reports or decisions.
Clean, consistent data improves accuracy across analytics, reporting, and operations. It ensures that teams work with reliable information and supports better decision-making across the business.
Scaling while staying in control of your data
Growth brings more customers, more transactions, and a surge of data. A well-designed data ingestion process helps you grow faster. You maintain control even as information volumes rise. Instead of struggling with expanding datasets, your systems adjust.
Imagine an online store on Black Friday. Orders triple overnight. Customer interactions increase across channels. Without scalable ingestion, this flood of data can overwhelm systems and hide important insights. With scalable ingestion, every piece of data flows into one central system. The result is a clear view of operations and faster decisions, even at peak demand.
Cost reduction
Data ingestion cuts the time and effort spent on manual data collection and cleaning. Automating these processes frees up resources and speeds up operations. Using as-a-service ingestion adds another benefit: no upfront investment in infrastructure.
For example, a retailer using automated ingestion can pull sales, inventory, and customer data from multiple systems without manual exports or spreadsheets. This saves staff hours each week and reduces errors in reporting.
As you can see, data ingestion brings real benefits to your business. First, it saves costs and boosts efficiency. Second, it improves data quality and makes information more accessible. Finally, it gives you better control and helps prevent data chaos.
If you need help with data management, contact us. With our expertise, we can help you structure, manage, and optimize your data to streamline operations and drive your business forward.
Which Data Ingestion Type Fits Your Business?
There’s no single data ingestion method that fits every business. The variety of options shows that the right choice depends on your specific needs. Here are the techniques we recommend considering when making your decision:
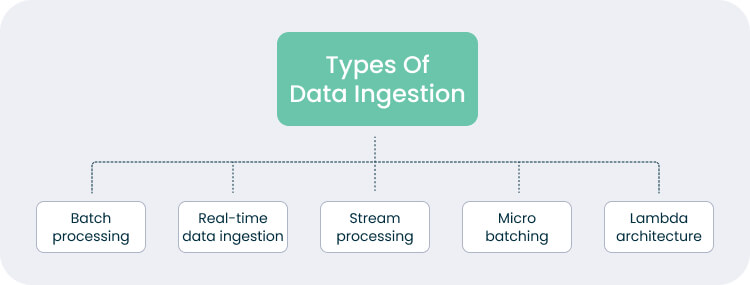
- Batch processing: It collects raw data over a set period, like daily sales reports or monthly financial statements, and processes it all at once. It’s simple, reliable, and has minimal impact on system performance since it can run during off-peak hours.
- Real-time data ingestion: This method captures data as soon as it’s generated. This provides instant insights and facilitates rapid decision-making.
- Stream processing: This technique resembles real-time ingestion, but it continuously analyzes data as it appears.
- Microbatching: This data ingestion type is something between batch and real-time processing. It ingests small, frequent batches, providing near instant updates without the heavy resource demands of fully live systems.
- Lambda architecture: This method combines batch and real-time processing. It handles large volumes of historical data while simultaneously managing real-time data streams.
When choosing a data ingestion type, consider these criteria: your application type, the nature of your data, security requirements, and the need for real-time streaming. This will help you determine whether a single method meets your needs or if you should combine several approaches.
Looking for the right data ingestion tool? Download our free guide to find your best fit!
Get Pdf

How Data Ingestion Works: The Key Stages
A solid data ingestion pipeline is more than moving data from point A to point B. It delivers clean, usable data that powers business insights. To make ingestion reliable, follow the key stages below and plan each one carefully:
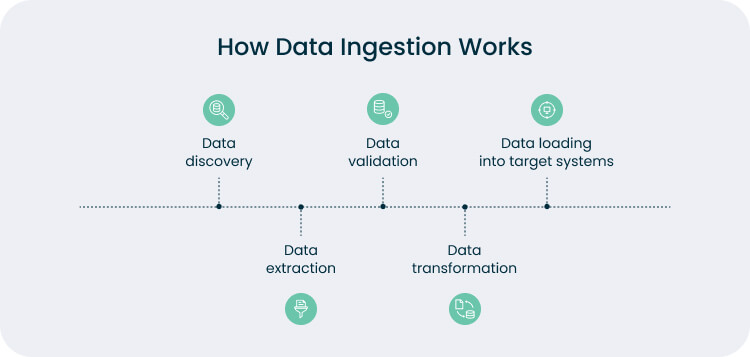
Stage 1: Data discovery
Before you ingest data, you need to know what you’re dealing with. Discovery is all about asking: What data exists, where it is stored, and why it matters? Large organizations often use catalog databases, APIs, SaaS platforms, third-party feeds, and data warehouses. Tools help automate, but business input is crucial. The goal is to document sources and confirm which support analytics goals.
Stage 2: Data extraction
Data extraction connects to data sources and retrieves information via SQL queries, REST APIs, file transfers, or streaming feeds. The challenge is managing diverse formats and protocols without errors. While connectors cover common platforms like Salesforce or Google Analytics, custom code is often needed for complex or less standardized sources.
Stage 3: Data validation
Data validation ensures raw data is accurate and reliable before entering storage. Checks cover file integrity, record counts, schema conformity, missing values, duplicates, and outliers. Invalid records are flagged or quarantined to protect quality. Some organizations use “data firewalls” that halt pipelines when anomalies, like empty or oversized files, appear.
Stage 4: Data transformation
Data transformation shapes raw data into usable formats, following ETL or ELT patterns. It can standardize formats, normalize values, enrich records, and filter noise. For example, IoT pipelines convert sensor readings to standard units and remove errors. Modern ELT pipelines often defer complex transformations to the warehouse for efficiency.
Stage 5: Loading into target systems
Loading delivers data to its target system: a warehouse, lake, or specialized database, using batch or streaming methods. Batch handles large volumes at intervals, while streaming updates in real time. Platforms like Snowflake, BigQuery, Kafka, or Kinesis optimize performance, ensuring data is ready for analysis, dashboards, or downstream applications.
Each stage of data ingestion plays a crucial role in turning raw data into actionable insights. When executed carefully, these steps create a reliable foundation for analytics, BI, and machine learning; when neglected, they lead to errors, inefficiency, and isolated data silos.
From data engineering to smart data solutions, we help turn your raw data into a powerful business asset. Get in touch today and start turning insights into action.
What Challenges Can You Face During Data Ingestion?
Now that you understand the value of data ingestion, it’s time to look at the obstacles that can complicate the process. Knowing them in advance helps you prepare and handle them more easily. Key challenges include:
- Time efficiency: Manual ingestion is slow and repetitive. Engineers spend hours coding connectors and mappings instead of focusing on high-value tasks. Automation helps, but not all sources have ready-made connectors.
- Schema changes & complexity: Even small changes in source data can break pipelines or create new tables, affecting transformations. Data is diverse, constantly evolving, and spread across departments, making it hard to keep up.
- Changing ETL schedules: Shifts in how frequently data sources deliver information can disrupt pipelines, skew metrics, and impact downstream processes.
- Parallel architectures: Batch and streaming data require different architectures, adding complexity and extra resources to manage.
- Job failures & data loss: Pipelines and orchestrators can fail, causing stale data or lost records. Choosing reliable tools is critical.
- Compliance requirements: Sensitive data must be handled carefully. Poor ingestion can result in regulatory fines or loss of customer trust.
Data ingestion isn’t easy. But by understanding these challenges, you can design pipelines that are resilient, efficient, and reliable.
How Forbytes Approaches the Data Ingestion Process
Managing lots of data from different systems can quickly become overwhelming. At Forbytes, we help turn scattered, messy information into clear insights you can actually use. The NoWaste project shows how a smart data ingestion approach can make operations smoother and reporting easier.
NoWaste, a leading European logistics company operating multiple warehouses, set out to turn inconsistent, siloed data from systems like WMS, HR, and ERP into a unified BI platform. The goal was to improve pricing strategies, reduce invoicing and reporting errors, and enable faster, data-driven decisions.
Incremental data ingestion
We set up ETL pipelines using Databricks notebooks and orchestration to handle incremental loads from each source system. Data was converted into Parquet files for efficient storage and fast retrieval, allowing NoWaste to ingest large volumes reliably without overloading pipelines.
Data lakehouse with Medallion architecture
On Azure Data Lake Gen2, we organized data into three layers:
- Bronze: Raw source data archived for lineage, auditability, and reprocessing.
- Silver: Matched, merged, and cleansed data to create an enterprise view of key business entities.
- Gold: Enriched, business-ready data optimized for advanced analytics and reporting.
Data transformation & materialized views
Using dbt, we executed most transformations within Databricks, creating materialized views and pre-aggregated datasets. This reduced query complexity in Power BI and boosted dashboard performance.
Power BI for actionable insights
Our engineers built advanced dashboards tailored to operational metrics and invoicing. NoWaste could now explore complex datasets quickly, make informed decisions, and act on insights in real time.
By combining incremental ingestion, a structured lakehouse, efficient transformations, and advanced reporting, we helped NoWaste transform fragmented data into a reliable, high-performance BI system.

Turn Your Data into a Strategic Asset with Forbytes
Data ingestion isn’t just about moving data, it’s about making it accurate, timely, and ready to drive decisions.
At Forbytes, we use expertise in ETL pipelines, cloud architectures, and data transformation tools to create ingestion processes that are scalable, reliable, and built for your business. Fragmented or siloed data becomes a unified, actionable asset, powering analytics, reporting, and smarter decision-making.
Ready to unlock your data’s full potential? Contact Forbytes today and let’s build a high-performance platform that delivers trusted, actionable insights.

Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?
Our Engineers
Can Help
Are you ready to discover all benefits of running a business in the digital era?